
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 알고리즘
- 프로그래머스 sql 고득점 kit
- MySQL
- scanner
- String클래스
- 예외처리
- Linux
- 데이터 조회
- 웹개발
- github
- 자바
- 프로그래머스 SQL
- 리눅스
- 프로그래밍
- DML
- order by
- 정보처리기사필기요약
- JavaScript
- 클래스
- where
- 개발자
- 메서드
- 백엔드
- 프론트엔드
- select문
- BufferedReader
- 입출력
- html
- Git
- select
- 형변환
- 정보처리기사
- sql문
- SQL
- 백준
- 반복문
- for문
- StringBuilder
- 자바스크립트
- Java
- Today
- Total
ToBe끝판왕
[ 2과목 ] 소프트웨어 개발 본문

< 참고사항 >
※ 정보처리기사 개정된 후, 기출문제들 다 풀고 3회 정도 반복할 것!
※ 이해 안 되는 문제들은 유튜브를 통해서 이해할 것! ( 전문강사들이 문제풀이 영상 많음 )
※ 게시물은 자주 나오는 필기 기출 내용 위주이지만 스스로 다른 개념들도 확인해볼 것!
자료 구조의 분류
• 프로그램에서 사용하기 위한 자료를 기억장치의 공간내에서 저장하는 방법, 저장된 그룹내에 존재하는 자료간의 관계
처리방법등을 연구 분석하는것을 말한다.
• 자료를 효율적으로 사용하기 위해서 자료의 특성에 따라서 분류, 구성하고 저장 및 처리하는 모든 작업
• 문제 해결을 위해 데이터 값들을 연산자들이 효율적으로 접근하여 처리할 수 있도록 체계적으로 조직하여 표현하는 것
1) 선형구조( Liner Structure )
• 데이터 항목 사이의 관계가 1:1이며, 선후관계가 명확하게 한 개의 선의 형태를 갖는 리스트 구조
- 배열( Array )
- 스택( Stack )
- 큐( Queue )
- 데크( Deque )
- 선형 리스트( Liner List ) = 연속 리스트( 순차적임 ) , 연결 리스트( 순차적 X )
※ 배열
• 동일한 자료형의 데이터들이 같은 크기로 나열되어 순서를 갖고 있는 집합
• 정적인 자료 구조로, 기억장소의 추가가 어려움
• 데이터 삭제 시, 데이터가 저장되어 있던 기억장소는 빈 공간으로 남아있어 메모리 낭비 발생
• 배열은 반복적인 데이터 처리 작업에 적합한 구조
• 배열은 데이터마다 동일한 이름의 변수를 사용하여 처리가 간편
※ 선형 리스트
• 일정한 순서에 의해 나열된 구조
• 연속 리스트( Contiguous List )
- 일정한 순서에 의해 나열된 구조
- 배열과 같이 연속되는 기억장소에 저장되는 자료구조
- 기억장소 이용 효율은 밀도가 1로서 가장 좋다.
- 중간에 데이터를 삽입하기 위해서는 연속된 빈 공간이 있어야 하며, 자료의 삽입 및 삭제시 이동이 필요하다.
( = 데이터의 항목을 추가, 삭제하는것이 불편 )
• 연결 리스트( Linked List )
- 자료들을 반드시 연속적으로 배열시키지는 않고, 임의의 기억공간에 기억시키되 자료항목의 순서에 따라 노드의 포인터부분을
이용하여 서로 연결시킨 자료 구조
- 노드의 삽입 , 삭제 작업이 용이
- 기억 공간이 연속적으로 놓여 있지 않아도 저장 가능
- 연결을 위한 링크( 포인터 ) 부분이 필요하기 때문에 순차리스트에 비해 기억공간의 이용 효율이 좋지 않다.
- 연결을 해주는 포인터( Pointer ) 를 위한 추가 공간이 필요하다.
- 중간 노드 연결이 끊어지면 다음 노드를 찾기 힘들다.
2) 비선형 구조( Non-Liner Structure )
데이터 항목 사이의 관계가 1:n ( 혹은 n : m )인 그래프적 특성을 갖는 형태
• 트리( Tree )
• 그래프( Graph )
배열( Array )
• < 인덱스 , 원소 > 쌍의 집합
• 순차적 메모리 할당 방식
• 정적인 자료 구조
• 기억 장소의 추가가 어렵고, 메모리의 낭비가 발생
• 첨자를 이용
• 반복적인 데이터 처리 작업에 적합한 구조
• 데이터마다 동일한 이름의 변수를 사용 ( 처리가 간편 )
스택( Stack )
• 리스트의 한쪽 끝으로만 자료의 삽입 / 삭제 작업이 이루어지는 자료 구조
• 후입 선출( LIFO : Last In First Out ) : 나중에 삽입된 자료가 가장 먼저 삭제됨
• 모든 기억공간이 꽉 채워져 있는 상태에서 데이터가 삽입되면 오버플로( Overflow ) 발생
• 더 이상 삭제할 데이터가 없는 상태에서 데이터를 삭제하면 언더 플로( Underflow ) 가 발생
• 서브루틴 호출 / 인터럽트 처리 / 수식 계산 및 수식 표기법에 응용
• 이용 연산 : 재귀 호출 / 후위 표현의 연산 / 깊이 우선 탐색
※ 스택 관련 용어
• TOP : 스택으로 할당된 기억공간에 가장 마지막으로 삽입된 자료가 기억된 위치
• Bottom : 스택의 가장 밑바닥
• PUSH : 자료의 삽입
• POP : 자료의 삭제
• M : 스택의 크기
• X : 스택의 이름
큐( Queue )
• 리스트의 한쪽에서는 삽입 / 다른 한쪽에서는 삭제가 이뤄지는 자료 구조
• 선입선출( FIFO :First In First Out ) 방식 : 가장 먼저 삽입된 자료가 가장 먼저 삭제됨
• 시작( F, Front )과 끝( R, Rear )을 표시하는 두 개의 포인터
• 운영체제의 작업 스케줄링에 사용
• 이용 연산 : 선택 정렬
※ 큐( Queue ) 관련 용어
• 프런트 포인터 : 가장 먼저 삽입된 기억공간을 가리키며, 삭제 작업시 사용
• 리어 포인터 : 가장 마지막에 삽입된 자료가 위치한 기억공간을 가리키며, 삽입 작업시 사용
데크( Deque )
• 리스트의 양쪽 끝에서 삽입 / 삭제 작업을 할 수 있는 자료 구조
• Double Ended Queue 의 약자
• Stack과 Queue의 장점만 가져와서 구성
• 입력이 한쪽에서만 발생하고, 출력은 양쪽에서 일어날 수 있는 입력 제한
- Scroll
• 입력은 양쪽에서 일어나고 출력은 한곳에서만 이루어지는 출력 제한
- Shelf
트리( Tree )
• 정점( Node, 노드 ) , 선분( Branch, 가지 )을 이용해 사이클을 이루지 않도록 구성한 그래프( graph )의 특수한 형태
• 노드( Node ) : 트리의 기본 요소, 자료항목과 다른 항목에 대한 가지를 합친 것
• 링크( Link ) : 노드와 노드를 연결한 선
• 근 노드( Root Node ) : 트리의 맨 위에 있는 노드
• 디그리( Degree, 차수 ) : 각 노드에서 뻗어 나온 가지의 수
• 단말 노드( Terminal Node ) : 자식이 하나도 없는 노드 ( Degree = 0 )
• 자식 노드( Son Node ) : 어떤 노드에 연결된 다음 레벨의 노드
• 부모 노드( Parent Node ) : 어떤 노드에 연결된 이전 레벨의 노드
• 형제 노드( Brother Node, Sibling ) : 동일한 부모를 갖는 노드
• 트리의 디그리 : 노드들의 디그리 중에서 가장 많은 수
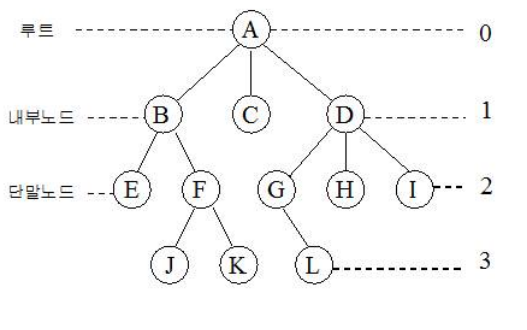
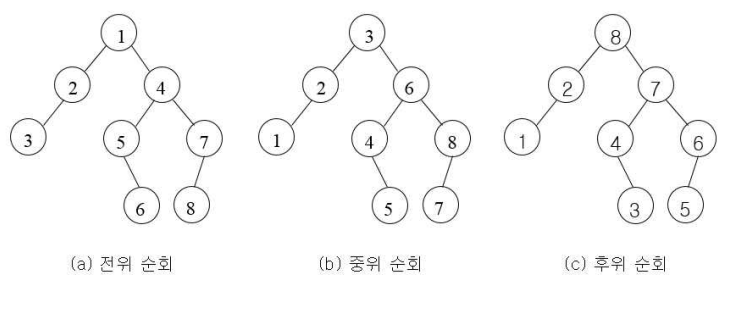
• 트리 순회 방법
- 전위 순회( preorder traversal ) : Root -> Left -> Right
- 중위 순회( inorder traversal ) : Left -> Root -> Right
- 후위 순회( postorder trabersal ) : Left -> Right -> Root
그래프( Graph )
1) 방향 그래프
• 정점을 연결하는 선에 방향이 있는 그래프
• n개의 정점으로 구성된 방향 그래프의 최대 간선 수 = n(n-1)
2) 무방향 그래프
• 정점을 연결하는 선에 방향이 없는 그래프
• n개의 정점으로 구성된 무방향 그래프의 최대 간선 수 = n(n-1)/2
ex) 퀵 정렬
데이터베이스( Database )
•
• 공용된 데이터( Shared Data ) : 여러 응용시스템이 공동으로 소유 및 유지
• 통합된 데이터( Integrated Data ) : 자료의 중복을 최대한 베재한 데이터의 모임
• 운영 데이터( Operational Data ) : 고유한 업무를 수행하는데 없어서는 안 될 자료
• 저장된 데이터( Stroed Data ) : 저장매체에 저장된 자료
DBMS( Database management System )
사용자와 데이터베이스 사이에서 사용자의 요구에 따라 정보를 생성
데이터베이스를 관리해주는 소프트웨어
• 정의 기능 : 데이터베이스에 저장될 데이터의 타입과 구조에 대한 정의 / 이용방식 제약조건 등을 명시 ( DDL )
• 조작 기능 : 사용자와 데이터베이스 사이의 인터페이스 수단을 제공 ( DML )
• 제어 기능 : 무결성 / 보안 / 권한 / 병행 제어 ( DCL )
데이터의 입 / 출력
1) SQL( Structured Query Language )
• 데이터의 정의어( DDL : Data Define Language )
DOMAIN( 도메인 ) / SCHEMA( 스키마 ) / TABLE( 테이블 ) / VIEW( 뷰 ) / INDEX( 인덱스 )
를 정의하거나 변경 / 삭제할 때 사용하는 언어
• 데이터 조작어( DML : Data Manipulation Language )
SELECT( 검색 ) / INSERT( 삽입 ) / UPDATE( 갱신 ) / DELETE( 삭제 )로 저장된 데이터를 실질적으로 처리하는 데 사용하는 언어
• 데이터 제어어( DCL : Data Control Language )
데이터의 무결성 / 보안 / 회복 / 병행 제어 등을 정의하는 데 사용하는 언어
2) 데이터 접속( Data Mapping )
소프트웨어의 기능 구현을 위해 프로그래밍 코드와 데이터베이스의 데이터를
연결( Mapping ) 하는 것
• SQL Mapping
프로그래밍 코드 내 SQL을 직접 입력해 DBMS의 데이터에 접속하는 기술
ex) JDBC / ODBC / MyBatis
• ORM( Object-Relational Mapping )
객체( Object )와 관계형 데이터베이스( RDB )의 데이터를 연결하는 기술
ex) JPA / Hibernate / Django
3) 트랜잭션( Transaction )
데이터베이스의 상태를 변환시키는 하나의 논리적 기능을 수행하기 위한 작업
한꺼번에 모두 수행되어야 할 일련의 연산
• Commit
트랜잭션 처리가 정상적으로 종료되어 수행한 변경내용을 DB에 반영하는 명령어
• Rollback
트랜잭션 처리가 비정상적으로 종료되어 DB의 일관성이 깨졌을 때, 트랜잭션이
행한 모든 변경 작업을 취소하고 이전 상태로 되돌리는 연산
• SavePoint( =CheckPoint )
트랜잭션 내에서 RollBack 할 위치인 저장점을 지정하는 명령어
• 트랜잭션의 특징
원자성 / 일관성 / 독립성 / 영속성
개발 지원 도구
1) 통합 개발 환경( IDE : Integranted Development Environment )
개발에 필요한 환경, 즉 편집기( Editor ) / 디버거( Debugger ) 등의 다양한 툴을 하나의 인터페이스로 통합하여 제공하는 것
ex) 이클립스( Eclipse ) / 비주얼 스튜디오( Visual Studio ) / 엑스 코드( X Code )
2) 빌드 자동화 도구
소스코드를 소프트웨어로 변환하는 과정에 필요한 전처리( Preprocessing ) / 컴파일( Compile ) 등의 작업들을
수행하는 소프트웨어
ex) Maven / Gradle / Jenkins
3) 기타 협업 도구( Groupware, 그룹웨어 )
• 일정관리 도구 : 구글 캘린더
• 프로젝트 관리 도구 : 트렐로 / 지라
• 형상 관리 도구 : 깃허브( GitHub )
• 디자인 도구 : 스케치 / 제플린
• 아이디어 공유 도구 : 에버노트
• 정보 공유 및 커뮤니케이션 도구 : 슬랙 / 잔디 / 태스크 월드
소프트웨어 패키징
1) 개요
• 모듈별로 생성한 실행 파일들을 묶어 배포용 설치 파일을 만드는 것
• 개발자가 아닌 사용자를 중심으로 진행
2) 고려사항
• 운영체제( OS ) / CPU / 메모리 등에 필요한 최소 환경을 정의
• 하드웨어와 함께 관리될 수 있도록 Managed Service 형태로 제공
• 다양한 사용자의 요구사항 반영
3) 패키징 작업 순서
기능 식별 > 모듈화 > 빌드 진행 > 사용자 환경 분석 > 패키징 및 적용 시험 > 패키징 변경 개선 > 배포
4) 제품 소프트웨어 패키징 도구 활용 시 고려사항
• 패키징 시, 사용자에게 배포되는 SW 이므로 보안 고려
• 사용자 편의성을 위한 복잡성 및 비효율성 문제 고려
• 제품 SW 종류에 적합한 암호화 알고리즘 적용
• 다양한 이기종 연동 고려
디지털 저작권 관리
1) 디지털 저작권 관리( DRM : Digital Right Management )의 흐름
• 콘텐츠 제공자( Contents Provider ) : 콘텐츠를 제공하는 저작권자
• 콘텐츠 분배자( Contents Distributor ) : 암호화된 콘텐츠를 유통하는 곳이나 사람
• 콘텐츠 소비자( Customer ) : 콘텐츠를 구매해서 사용하는 주체
• 패키저 ( Packager ) : 콘텐츠를 메타 데이터와 함께 배포 가능한 형태로 묶어 암호화하는 프로그램
• 클리어링 하우스( Clearing House ) : 저작권에 대한 사용 권한 / 라이선스 발급 / 사용량에 따른 결제 관리 등을 수행하는 곳
• DRM 컨트롤러 : 배포된 콘텐츠의 이용권한을 통제하는 프로그램
• 보안 컨테이너( Security Container ) : 콘텐츠 원본을 안전하게 유통하기 위한 전자적 보안 장치
2) 디지털 저작권 관리의 기술요소
• 암호화( Encryption ) : 콘텐츠 및 라이선스를 암호화하고 전자 서명할 수 있는 기술
• 키 관리( Key Management ) : 콘텐츠를 암호화한 키에 대한 저장 및 분배 기술
• 식별 기술( Identification ) : 콘텐츠에 대한 식별 체계 표현 기술
• 저작권 표현( Right Expression ) : 라이선스의 내용 표현 기술
• 암호화 파일 생성( Packager ) : 콘텐츠를 암호화된 콘텐츠로 생성하기 위한 기술
• 정책관리( Policy Management ) : 라이선스 발급 및 사용에 대한 정책 표현 및 관리 기술
• 크랙 방지( Tamper Resistance ) : 크랙에 의한 콘텐츠 사용 방지 기술
• 인증( Autehntication ) : 라이선스 발급 및 사용의 기준이 되는 사용자 인증기술
형상관리
1) 소프트웨어 패키징 형상관리 ( SCM : Software Configuaration Management )
• 형상관리는 소프트웨어의 개발과정에서 소프트웨어의 변경사항을 관리하기 위한 활동
• 소프트웨어 개발의 전 단계에 적용되는 활동 ( 유지보수 단계에서도 수행 )
2) 형상관리의 중요성
• 소프트웨어의 변경사항을 체계적으로 추적하고 통제할 수 있다.
• 제품 소프트웨어에 대한 무절제한 변경 방지
• 진행 정도를 확인하기 위한 기준으로 사용될 수 있다.
3) 형상관리 기능
• 형상 식별
• 형상 통제( 변경 관리 )
• 형상 감사
• 형상 기록( 상태 보고 )
• 버전 제어
4) 제품 소프트웨어의 형상관리 역할
• 형상관리를 통해 이전 리비전이나 버전에 대한 정보에 접근 가능 / 배포본 관리에 유용
• 불필요한 사용자의 소스 수정 제한
• 동일한 프로젝트에 대해 여러 개발자 동시 개발 가능
5) 형상관리 도구 주요 기능
|
명령어
|
설명
|
|
저장소
( Repository )
|
최신 버전의 파일들과 변경 내역에 대한 정보들이 저장되어 있는 곳
|
|
가져오기
( Import )
|
버전 관리가 되고 있지 않은 아무것도 없는 저장소 ( Repository )에
처음으로 파일을 복사하는 것
|
|
체크아웃
( Check-Out )
|
프로그램을 수정하기 위해 저장소( Repository )에서 파일을 받아오는 것
|
|
체크인
(Check-In )
|
체크아웃 한 파일의 수정을 완료한 후, 저장소의 파일을 새로운 버전으로 갱신하는 것
|
|
커밋
( Commit )
|
체크인을 수행할 때 , 이전에 갱신된 내용이 있는 경우에는 충돌
( Confilct )을 알리고 diff도구를 이용해 수정한 후, 갱신 완료
|
|
동기화
( Update )
|
저장소에 있는 최신 버전으로 자신의 작업공간( 로컬/지역 저장소 )
을 동기화하는 것
|
6) 형상관리 관리 항목
• 프로젝트 요구 분석서
• 소스코드
• 운영 및 설치 지침서
• 프로젝트 개발 비용
애플리케이션 테스트
1) 정의
• 애플리케이션에 잠재되어 있는 결함을 찾아내는 일련의 행위 / 절차
• 개발된 소프트웨어가 고객의 요구사항을 만족시키는지 확인( Validation )
• 소프트웨어가 기능을 정확히 수행하는지 검증( Verfication )
2) 애플리케이션 테스트의 분류
• 프로그램 실행 여부에 따른 테스트
- 정적 테스트
프로그램을 실행하지 않고 명세서나 소스코드를 대상으로 분석
ex) 워크 스루 / 인스펙션 / 코드 검사
- 동적 테스트
프로그램을 실행하여 오류를 찾는 테스트
ex) 화이트박스 테스트 / 블랙박스 테스트
※ 워크 스루
• 사용 사례를 확장하여 명세하거나 설계 다이어그램, 원시 코드, 테스트 케이스 등에 적용 가능
• 복잡한 알고리즘 또는 반복, 실시간 동작, 병행 처리와 같은 기능이나 동작을
이해하려고 할 때 유용
• 단순한 테스트 케이스를 이용하여 프로덕트를 수작업으로 수행해 보는 것
※ 인스펙션 순서
계획 > 사전교육 > 준비 > 인스펙션 회의 > 수정 > 후속조치
• 테스트 기반에 따른 테스트
- 명세 기반 테스트
사용자의 요구사항에 대한 명세를 빠짐없이 테스트 케이스로 만들어 구현하는지 확인
- 구조 기반 테스트
소프트웨어 내부의 논리 흐름에 따라 테스트 케이스를 작성하고 확인
- 경험 기반 테스트
테스터의 경험을 기반으로 수행하는 테스트
• 시각에 따른 테스트
- 검증( Verification ) 테스트 : 개발자의 시각에서 제품의 생산과정을 테스트
- 검증 테스트 : 소프트웨어가 요구사항에 부합하게 구현되었음을 보장하는 활동
ex) 단위 테스트 / 통합 테스트 / 시스템 테스트
- 확인( Validation ) 테스트 : 사용자의 시각에서 생산된 제품의 결과를 테스트
- 확인 테스트 : 소프트웨어가 고객의 의도에 따라 구현되었음을 보장하는 활동
ex) 인수 테스트( 알파 / 베타 테스트 )
※ 단위 테스트
· 구현 단계에서 각 모듈의 개발을 완료한 후, 개발자가 명세서의 내용대로 정확히 구현되었는지
테스트한다.
· 모듈 내부의 구조를 구체적으로 볼 수 있는 구조적 테스트를 주로 시행한다.
· 테스트할 모듈을 호출하는 모듈도 있고, 테스트할 모듈이 호출하는 모듈도 있다.
※ 단위 테스트 도구
· CppUnit
· JUnit
· HttpUnit
3) 검증( Validation 검사 기법 )
• 동치 분할 검사 : 입력 자료에 초점을 맞춰 케이스를 만들고 검사
( 블랙박스 테스트 종류 )
• 알파 테스트 : 개발자의 장소에서 사용자가 개발자 앞에서 행하는 테스트
통제된 환경에서 사용자와 개발자가 함께 확인하며 수행
( 인수 테스트 종류 )
• 베타 테스트 : 선정된 최종 사용자가 여러 명의 사용자 앞에서 행하는 테스트
( 인수 테스트 종류, 개발자 없이 시행 )
통합 테스트( Integration Test )
• 시스템을 구성하는 모듈의 인터페이스와 결합을 테스트하는 것
• 모듈 간의 인터페이스와 시스템의 동작이 정상 적으로 잘되고 있는지를 빨리 파악하고자 할 때
상향식보다는 하향식 통합 테스트가 더 좋다.
1) 상향식 통합 테스트( Bottom Up Integration Test )
• 프로그램의 하위 모듈에서 상위 모듈 방향으로 통합하면서 테스트
• 하나의 주요 제어 모듈과 종속 모듈의 그룹인 클러스터( Cluster ) 필요
2) 하향식 통합 테스트( Top Down Integration Test )
• 프로그램의 상위 모듈에서 하위 모듈 방향으로 통합하면서 테스트
• 깊이 우선 통합법 / 넓이 우선 통합법 사용
• 테스트 초기부터 사용자에게 시스템 구조를 보여줄 수 있음
• 상위 모듈에서는 테스트 케이스 사용하기 어려움
• 순서
1) 주요 제어 모듈 작성된 프로그램 사용, 주요 제어 모듈의 종속 모듈은 스텁( Stub )으로 대체
2) 깊이 우선 / 넓이 우선 통합 방식에 따라 스텁( Stub )들이 한 번에 하나씩 실제 모듈로 교체
3) 모듈이 통합될 때마다 테스트 실시
4) 새로운 오류가 발생하지 않음을 보증하기 위해 회귀 테스트 실시
3) 혼합식 통합 테스트
· 하위 수준에서는 상향식 통합 / 상위 수준에서는 하향식 통합 사용해 최적의
· 테스트를 지원하는 방식
· 샌드위치( Sandwich ) 식 통합 테스트 방법
테스트 관련 용어
1) 테스트 케이스
• 구현된 소프트웨어가 사용자의 요구사항을 정확하게 준수했는지를 확인하기 위해 설계된 입력 값, 실행 조건, 기대 결과
등으로 구성된 테스트 항목에 대한 명세서
• 프로그램에 결함이 있더라도 입력에 대해 정상적인 결과를 낼 수 있기 때문에 결함을 검사할 수 있는 테스트 케이스를
찾는 것이 중요
※ 테스트 케이스 구성요소
• 입력 명세( 테스트 조건 / 테스트 데이터 )
• 출력 명세( 테스트 예상 결과 )
• 식별자( 항목 식별자 / 일련번호 )
• 환경설정( 필요 하드웨어 , 소프트웨어의 환경 )
2) 테스트 시나리오
테스트 케이스를 적용하는 순서에 따라 여러 개의 테스트 케이스들을 묶은 집합
3) 테스트 오라클
테스트의 결과가 참인지 거짓인지를 판단하기 위해서 사전에 정의된 참값을 입력하여
비교하는 기법 및 활동
( 참 / 샘플링 / 휴리스틱 / 일관성 검사가 존재 )
애플리케이션 성능 분석
1) 성능 분석 항목
• 처리량( Throughput ) : 일정 시간 내 애플리케이션이 처리하는 일의 양
• 응답 시간( Response Time ) : 요청을 전달한 시간부터 응답이 도착할 때까지 걸린 시간
• 경과시간( Turn Around Time ) : 작업을 의뢰한 시간부터 처리가 완료될 때까지 걸린 시간
• 자원 사용률( Resource Usage ) : 의뢰한 작업을 처리하는 동안의 CPU 사용량 / 메모리 사용량 / 네트워크 사용량 등
2) 애플리케이션 성능 저하 원인 분석
• DB에 필요 이상의 많은 데이터를 요청한 경우
• 커넥션 풀( Connection Pool )의 크기를 너무 작거나 크게 설정한 경우
• JDBC나 ODBC 같은 미들웨어를 사용한 후, 종료하지 않아 연결 누수가 발생한 경우
• 대량의 파일을 업로드하거나 다운로드해 처리시간이 길어진 경우
3) 소스코드 최적화
• 클린 코드( Clean Code ) 작성 원칙
• 가독성 / 단순성 / 의존성 배제 / 중복성 최소화 / 추상화
4) 소스코드 품질분석 도구의 종류
• 정적 분석도구 : Pmd / Cppcheck / Checkstyle / SonarQube / Ccm / Cobetuna
• 동적 분석 도구 : Avalanche / Valgrind
모듈 연계
1) EAI(Enterpriser Application Integration )
• 기업 내 각종 애플리케이션 및 플랫폼 간의 정보전달 / 연계 / 통합 등
• 상호 연동이 가능하게 해주는 설루션
• 포인트 투 포인트( Point to Point )
- 점 대 점으로 연결하는 방식 / 변경 및 재사용이 어려움
• 허브 앤 스포크( Hub & Spoke )
- 단일 접점인 허브( Hub ) 시스템을 통해 데이터를 전송하는 중앙 집중형 방식
- 확장 및 유지보수가 용이하지만 허브 장애 발생 시, 시스템 전체에 영향
• 메시지 버스( Message Bus , ESB 방식 )
- 애플리케이션 사이에 미들웨어를 둬 처리하는 방식 , 확장성이 뛰어나며 대용량 처리 가능
• 하이브리드( Hybrid )
- Hub & Spoke와 Message Bus의 혼합 방식 / 데이터 병목 현상을 최소화
2) ESB( Enterprise service Bus )
• 애플리케이션 간 연계 / 데이터 변환 / 웹서비스 지원 등 표준 기반의 인터페이스를 제공하는 설루션
• 서비스 중심의 통합을 지향 / 결합도( Coupling )를 약하게 유지
• 관리 및 보안 유지가 쉽고 / 높은 수준의 품질 지원 가능
인터페이스 구현 & 인터페이스 보안
1) 데이터 통신을 이용한 인터페이스 구현
• 애플리케이션 영역에서 인터페이스 형식에 맞춘 데이터 포맷을 인터페이스 대상으로 전송하고 이를 수신 측에서
파싱( Parsing ) 해 해석하는 방식
• 주로 JSON이나 XML 형식의 데이터 포맷을 사용해 인터페이스 구현
2) 인터페이스 엔터티를 이용한 인터페이스 구현
• 인터페이스가 필요한 시스템 사이에 별도의 인터페이스 엔터티로 상호 연계하는 방식
• 일반적으로 인터페이스 테이블을 엔터티로 활용
• 송/수신 인터페이스 테이블의 구조는 상황에 따라 서로 다르게 설계
3) 인터페이스 보안 기능 적용
• 네트워크( Network ) / 애플리케이션( Application ) / 데이터베이스( Database ) 영역
• 스니핑( Sniffing ) : 네트워크의 중간에서 남의 패킷 정보를 도청하는 해킹 유형
• 시큐어 코딩( Secure Coding ) : 소프트웨어 개발 과정에서 지켜야 할 일련의 보안 활동
※ 인터페이스 구현 기술
Ajax : JavaScript를 사용한 비동기 통신기술로 클라이언트와 서버 간에 XML 데이터
를 주고받는 기술
인터페이스 구현 검증 / 인터페이스 오류 확인
1) 인터페이스 구현 검증 도구
|
도구
|
기능
|
|
xUnit
|
Java( Junit ) , C++( Cppunit ), .Net( Nunit ) 등 다양한 언어를
지원하는 단위테스트 프레임워크
|
|
STAF
|
서비스 호출 및 컴포넌트 재사용 등 다양한 환경을 지원하는
테스트 프레임워크
|
|
FitNesse
|
웹 기반 테스트케이스 설계 / 실행 / 결과 확인 등을 지원하는
테스트 프레임워크
|
|
NTAF
|
STAF 의 장점인 재사용 및 확장성과 FitNesse의 장점인 협업기능을
통합한 NHN( Naver )의 테스트 자동화 프레임워크
|
|
Selenuim
|
다양한 브라우저 및 개발 언어를 지원하는 웹 애플리케이션
테스트 프레임워크
|
|
Watir
|
Ruby 언어를 사용하는 애플리케이션 테스트 프레임워크
|
2) 인터페이스 오류 발생 즉시 확인
• 오류 메시지 알람 표시
• 오류 SMS 발송
• 오류 내역 이메일 발송
3) 인터페이스 오류 발생 주기적인 확인
|
오류 확인 방법
|
특징
|
|
인터페이스 오류 로그 확인
|
오류를 별도의 로그파일로 생성해 보관
자세한 오류 원인 및 내역을 확인 가능
|
|
인터페이스 오류 테이블 확인
|
오류사항의 확인이 쉬워 관리가 용이
오류사항이 구체적이지 않아 별도의 분석 필요
|
|
인터페이스 감시( APM ) 도구 사용
|
스카우터( Scouter ) 나 제니퍼( Jennifer ) 등의 인터페이스 감시도구를 사용해 주기적 확인
|
알고리즘/ 알고리즘 설계 기법
1) 알고리즘이란?
• 주어진 작업을 수행하는 컴퓨터 명령어를 순서대로 나열한 것
• 컴퓨터로 문제를 풀기 위한 단계적인 절차
• 검색(Searching ) 은 정렬이 되지 않은 데이터 혹은 정렬이 된 데이터 중에서 키값에
해당하는 데이터를 찾는 알고리즘
• 정렬( Sorting )은 흩어져 있는 데이터를 키값을 이용하여 순서대로 열거하는 알고리즘
2) 알고리즘 설계
|
기법
|
설명
|
|
분할과 정복
(Divde and Conquer )
|
문제를 나눌 수 없을 때까지 나누고, 각각을 풀면서 다시 병합해
문제의 답을 얻는 알고리즘
|
|
동적계획법
(Dynamic Programming)
|
어떤 문제를 풀기 위해 그 문제를 더 작은 문제의 연장선으로
생각하고, 과거에 구한 해를 활용하는 방식의 알고리즘
|
|
탐욕법
(Greedy)
|
결정을 해야 할 때마다, 그 순간에 가장 좋다고 생각되는 것을
해답으로 선택하는 알고리즘
|
|
백트래킹
(Backtracking)
|
어떤 노드의 유망성 점검 후, 유망하지 않으면 그 노드의 부모
노드로 되돌아가 다른 자손 노드를 검색하는 알고리즘
|
파티션( Partition )
|
종류
|
설명
|
|
레인지 파티셔닝
(Range Partitioning, 범위분할 )
|
지정한 열의 값을 기준으로 분할
ex) 일별 / 월별 / 분기별 등
|
|
해시 파티셔닝
(Hash Partitioning, 해시분할)
|
해시 함수에 따라 데이터 분할
|
|
리스트 파티셔닝
(List Partitioning)
|
미리 정해진 그룹핑 기준에 따라 분할
|
|
컴포지트 파티셔닝
(Composite Partitioning, 조합분할)
|
범위분할 이후 해시함수를 적용
ex) 범위분할 + 해시분할
|
• 장점 : 성능 향상 / 가용성 향상 / 백업 가능 / 경합 감소
시간 복잡도에 따른 알고리즘
1) 시간 복잡도란?
• 프로그램을 실행시켜 완료하는 데 걸리는 시간을 의미
• 컴파일 시간 + 실행 시간
※ 컴파일 시간 : 소스 프로그램을 컴파일하는 데 걸리는 시간 ( 고정적 )
※ 실행 시간 : 프로그램의 실행시간을 추정하기 위해 단위 명령문 하나를 실행하는 데 걸리는 시간과 실행 빈도수
|
복잡도
|
설명
|
대표 알고리즘
|
|
O(1)
|
상수형 복잡도
자료크기 무관하게 항상 일정한 속도로 작동
|
해시함수
(Hash Function)
|
|
O(logN)
|
로그형 복잡도
문제를 해결하기 위한 단계의 수가 log2N번만큼의
수행시간을 가짐
|
이진탐색
( Binary Search)
|
|
O(n)
|
선형 복잡도
입력자료를 차례로 하나씩 모두 처리
수행시간이 자료 크기와 직접적 관계로 변함( 정비례 )
|
순차탐색
( Sequential
Search )
|
|
O(N logN)
|
선형 로그형 복잡도
문제를 해결하기 위한 단계의 수가 Nlog2N번 만큼
수행시간을 가짐
|
퀵정렬
합병 정렬
|
|
O(N2)
|
제곱형 주요 처리 루프구조가 2중인 경우
N의 크기가 작을 땐 N2이 Nlog2N보다 느릴 수 있음
|
선택정렬
버블정렬
삽입정렬
|
※ 이진 검색 알고리즘
• 탐색 효율이 좋고 탐색 시간이 적게 소요된다.
• 검색할 데이터가 정렬되어 있어야 한다.
• 비교 횟수를 거듭할 때마다 검색 대상이 되는 데이터의 수가
• 절반으로 줄어든다.
• 이진 검색 방법 인터넷에서 한번 찾아서 1문제 풀어보기
※ 대표 알고리즘
• 퀵 정렬: 레코드의 많은 자료 이동을 없애고 하나의 파일을 부분적으로 나누어 가면서 정렬
• 삽입 정렬: 가장 간단한 정렬 / 이미 순서화된 파일에 새로운 하나의 레코드를 순서에 맞게 삽입시켜 정렬
• 쉘 정렬 : 삽입 정렬의 확장 개념 / 입력 파일을 매개변수 값으로 서브 파일을 구성하고 각 서브파일 삽입 정렬 방식으로
순서 배열하는 과정을 반복하는 정렬
• 버블 정렬 : 주어진 파일에서 인접한 두 개의 레코드 킷값을 비교하여 그 크기에 따라 레코드 위치를 서로 교환하는 정렬
• 힙 정렬 : 완전이진 트리를 이용한 정렬
• 2 Way 합병 정렬 : 이미 정렬되어 있는 두 개의 파일을 한 개의 파일로 합병하는 정렬
※ 힙( Heap Sort )
• 정렬한 입력 레코드들로 힙을 구성하고 가장 큰 킷값을 갖는 루트 노드를 제거하는 과정을 반복하여 정렬하는 기법
• 평균 수행 시간은 O(nlog2 n)이다.
• 완전 이진트리( Complete binary tree )로 입력자료의 레코드를 구성
• 평균과 최악 모두 시간 복잡도는 O(nlog2 n)이다.
※ 최악의 경우 검색 효율
• 이진 탐색 트리 : O(n) => 가장 안 좋음
• AVL 트리 : O( log n )
• 2-3 트리 : O( log 3n )
• 레드-블랙 트리 : O( log n )
화이트박스 테스트 / 블랙박스 테스트
1) 화이트박스 테스트
• 애플리케이션 테스트 ( 프로그램 직접 실행 테스트 종류 )
• 모듈 안의 내용( 작동 )을 직접 볼 수 있음
• 내부의 논리적인 모든 경로를 테스트해 테스트 케이스를 설계
• 소스코드( Source Code )의 모든 문장을 한번 이상 수행함으로써 진행
• 선택 / 반복 등의 부분들을 수행함으로써 논리적 경로 점검
|
종류
|
설명
|
|
기초 경로 검사
( Base Path Testing )
|
대표적인 화이트박스 테스트 기법
테스트 측정 결과는 실행 경로의 기초를 정의하는
지침으로 사용
|
|
제어 구조 검사
|
조건검사( Condition Testing )
: 논리적 조건을 테스트하는 기법
루프검사( Loop Testing )
: 반복( Loop ) 구조에 맞춰 테스트하는 기법
데이터 흐름검사( Data Flow Testing )
: 프로그램에서 변수의 정의와 변수 사용의 위치에 초점을
맞춰 테스트 하는 기법
|
2) 블랙박스 테스트
• 모듈 안에서 어떤 일( 작동) 이 일어나는지 알 수 없음
• 소프트웨어가 수행할 특정 기능을 알기 위해 각 기능이 완전히 작동되는 것을
• 입증하는 테스트 ( =기능 테스트 )
• 소프트웨어 인터페이스에서 실시되는 테스트
|
종류
|
설명
|
|
동치 분할 검사
( Equivalence
Partioning Testing )
|
프로그램의 입력 조건에 타당한 입력 자료와 타당하지 않은
입력자료의 개수를 균등하게 해 테스트 케이스를 정하고,
해당 입력 자료에 맞는 결과가 출력되는지 확인하는 기법
|
|
경계값 분석
( Boundary Value
Analysis )
|
입력조건의 중간값보다 경계값에서 오류가 발생될 확률이
높다는 점을 이용해 입력조건의 경계값을 테스트 케이스로
선정해 검사하는 기법
|
|
원인-효과 그래프 검사
( Cause-Effect Graphing Testing )
|
입력 데이터 간의 관계와 출력에 영향을 미치는 상황을
체계적으로 분석한 다음 효용성이 높은 테스트 케이스를
선정해 검사하는 기법
|
|
비교 검사
( Comparison Testing )
|
여러 버전의 프로그램에 동일한 테스트 자료를 제공해
동일한 결과가 출력되는지 테스트 하는 기법
|
|
오류 예측 검사
( Error Guessing )
|
다른 블랙박스 테스트 기법으로 찾아낼 수 없는 오류를
찾아내는 일련의 보충적 검사기법( 데이터 확인 검사 )
|
소프트웨어 품질 측정( 개발자 관점 고려 항목 )
• 정확성 / 신뢰성 / 효율성 / 무결성 / 유연성 / 이식성 / 재사용성 / 상호운용성
• 기능성 : 사용자 요구사항을 정확하게 만족하는 기능을 제공하는지 여부
• 신뢰성 : 요구된 기능을 정확하고 일관되게 오류 없이 수행하는 정도
• 사용성 : 사용자와 컴퓨터 사이에 발생하는 어떤 행위에 대해 사용자가 정확하게 이해하고 사용하며 향후 다시 사용하고
싶은 정도
• 효율성 : 요구하는 기능을 할당된 시간 동안 한정된 자원으로 얼마나 빨리 처리할 수 있는지 정도
• 유지 보수성 : 환경 변화 / 새 요구사항 발생 시 소프트웨어 개선 및 확장할 수 있는 정도
• 이식성 : 타 환경에서도 얼마나 쉽게 적용할 수 있는지 정도
인터페이스 보안
• 네트워크 영역에 적용될 수 있는 설루션 : IPSec / SSL / S-HTTP
• SMTP는 이메일 송/수신에 사용되는 프로토콜 ( 보안과 상관 X )
반정규화( Denormalization) 유형
• 중복 테이블 추가하는 방법
1) 진행 테이블의 추가
2) 집계 테이블의 추가
3) 특정 부분만을 포함하는 테이블 추가
소프트웨어 테스트 법칙
1) 오류의 80%는 전체 모듈의 20% 내에서 발견된다. : Pareto 법칙
2) 지연되는 프로젝트에 인력을 더 투입하면 오히려 더 늦어진다 : Brooks 법칙
McCabe의 cyclomatic 수 계산
• 제어 흐름 그래프 참조
Edge( 화살표 ) - Node( 동그라미 ) + 2
소프트웨어 재공학( 재개발에 비해 갖는 장점 )
• 위험부담 감소
• 비용 절감
• 시스템 명세의 오류 억제
• 개발 시간의 감소
소프트웨어 설치 매뉴얼
• 설치 과정에서 표시될 수 있는 예외상황에 관련 내용을 별도로 구분하여 설명한다.
• 설치 시작부터 완료할 때까지의 전 과정을 빠짐없이 순서대로 설명한다.
• 설치 매뉴얼은 사용자 기준으로 작성한다.
• 설치 매뉴얼에는 목차, 개요, 기본사항 등이 기본적으로 포함되어야 한다.
저장 장치 관련 개념
• 외부 스키마( External Schema )
- 사용자의 관점에서 보여주는 데이터베이스 구조
• 내부 스키마( Internal Schema )
- 저장장치의 입장에서 데이터베이스 전체가 저장되는 방법을 명세 ( 단하나만 존재 )
• 개념 스키마( Conceptual Schema )
- 전체 사용자 또는 모든 응용 시스템이 필요한 데이터베이스 구조
- 조직 전체의 데이터베이스로 단 하나만 존재
이분 검색 & 해싱 함수
1) 이분 검색
• 전체 파일을 두개의 서브파일로 분리해 가면서 Key 레코드를 검색하는 방식
• 반드시 순서화된 파일이어야 검색 가능
• 찾고자 하는 Key 값을 파일의 중간 레코드 Key 값과 비교하면서 검색
• 비교횟수를 거듭할 때마다 검색 대상이 되는 데이터의 수가 절반으로 줄어들어 탐색 효율이 좋고 시간이 적게 소요
• M = ( F + L ) / 2 ( F : 첫번째 레코드 번호 , L : 마지막 레코드 번호 , M : 중간 레코드 번호 )
2) 해싱
• 해시 테이블이라는 기억공간을 할당하고, 해시 함수를 이용하여 레코드를 해당 기억장소에서 저장하거나 검색작업 수행
• 해싱함수의 종류
- 제산법( Division ) : 키(K)를 해시표의 크기보다 큰 수중에서 가장 작은소수(Q)로 나눈 나머지를 홈 주소로 삼는다.
즉, h(k) = K mod Q
- 제곱법( Mid-Square ) : 키(K)를 제곱한 후, 그 중간 부분의 값을 홈 주소로 삼는다.
- 폴딩법( Folding ) : 키(K)을 여러 부분으로 나눈 후, 각 부분의 값을 더하거나 XOR(배타적 논리합)한 값을 홈 주소로 삼는다.
- 기수 변환법( Radix )
- 대수적 코딩법( Algebraic Coding )
- 숫자 분석법( Digit Analysis ) : 키 값을 이루는 숫자의 분포를 분석하여 비교적 고른 자리를 필요한 만큼 택해서 홈 주소로 삼는다.
- 무작위법( Random ) :
※ Collison( 충돌 현상 ) 해결법
• 체이닝( Chaining ) : Collison이 발생하면 버킷에 할당된 연길 리스트( Linked List )에 데이터를 저장
• 개방 주소법( Open Addressing ) : Collison이 발생하면 순차적으로 그 다음 빈 버킷을 찾아 데이터를 저장
• 재해싱( Rehashing ) : Collison이 발생하면 새로운 해싱 함수로 새로운 홈주소를 함
인터페이스 간의 통신을 위해 이용되는 데이터 포맷
• JSON
• XML
• YAML
NS Chart
• 논리의 기술에 중점을 두고 도형을 이용한 표현 방법이다.
• 이해하기 쉽고 코드 변환이 용이하다.
• 연속 / 선택 / 반복 등의 제어 논리 구조를 표현한다.
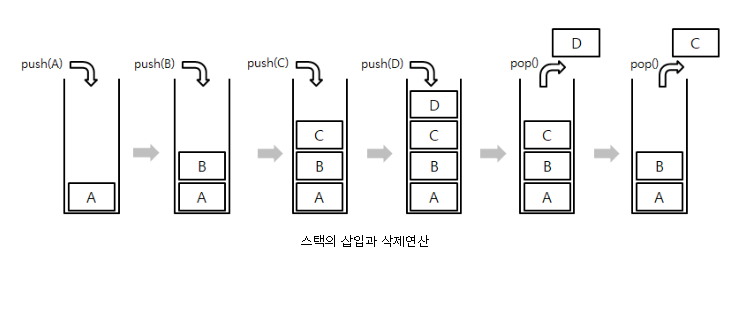
스택 연산 출력 결과
push() 명령어로 쌓이게 되고 pop() 명령어는 가장 마지막에 들어온 것이 나가게 된다.
코드 인스펙션
• 프로그램을 수행시켜보는 것 대신에 읽어보고 눈으로 확인하는 방법으로 볼 수 있다.
• 코드 품질 향상 기법 중 하나이다.
• 정적 테스트 시에만 활용하는 기법이다.
• 결함과 함께 코딩 표준 준수 여부 / 효율성 등의 다른 품질 이슈를 검사하기도 한다.
'■ 자격증 > 정보처리기사' 카테고리의 다른 글
| [ 5과목 ] 정보시스템 구축 관리 (0) | 2022.05.18 |
|---|---|
| [ 4과목 ] 프로그래밍 언어 활용 (0) | 2022.05.17 |
| [ 3과목 ] 데이터베이스 구축( DB ) (0) | 2022.05.16 |
| [ 1과목 ] 소프트웨어 설계 (0) | 2022.05.12 |



