
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 백준
- scanner
- 정보처리기사
- 리눅스
- 프로그래머스 sql 고득점 kit
- where
- JavaScript
- Git
- Java
- sql문
- 클래스
- 데이터 조회
- order by
- 프로그래머스 SQL
- 메서드
- 프론트엔드
- MySQL
- 프로그래밍
- DML
- 입출력
- 반복문
- StringBuilder
- 개발자
- 정보처리기사필기요약
- BufferedReader
- for문
- 백엔드
- github
- SQL
- String클래스
- select
- 자바스크립트
- html
- Linux
- 예외처리
- 알고리즘
- 웹개발
- select문
- 형변환
- 자바
- Today
- Total
ToBe끝판왕
[ JAVA ] 컬렉션 프레임워크 (2) - Set 본문

컬렉션 프레임워크 - HashSet
• List 와 Set 을 비교해보자

- List는 요소들의 순차적인 컬렉션
- List는 순서 유지 : 추가된 요소는 특정한 순서를 유지
- List는 중복 허용 : 같은 요소가 여러번 나올 수 있다.
- List는 인덱스 접근 가능 : 인덱스는 보통 0부터 시작하며 인덱스를 통하여 해당 요소를 알 수 있다.
- 예시 : 장바구니 목록 , 순서가 중요한 일련의 이벤트 목록 등
※ List에 대한 내용은 이 게시물에서 확인 가능하다.
https://baby9235.tistory.com/120
[ JAVA ] 컬렉션 프레임워크 (1) - List
컬렉션 프레임워크 - 배열 리스트 1) 배열이란 ? ▶ 배열 리스트에 대하여 알아보기 전, 배열에 대하여 먼저 파악하자 ! • 배열의 특징 - 배열의 길이 : .length 속성을 통해서 얻을 수
baby9235.tistory.com
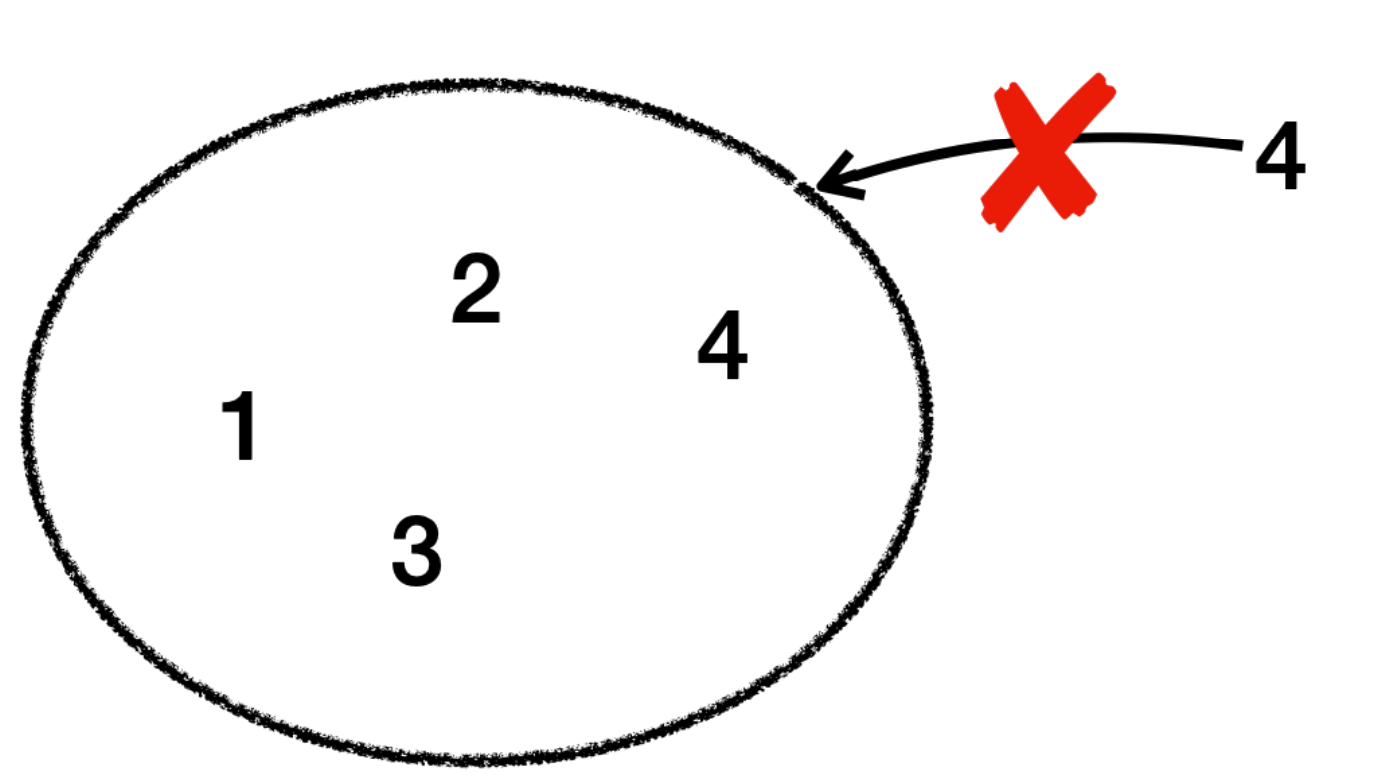
- Set은 유일한 요소들의 컬렉션
- Set의 유일성 : 중복된 요소가 존재하지 않는다. ( 이미 존재하는 요소를 추가할땐 무시된다. )
- Set의 순서 미보장 : 요소를 출력할 때, 입력 순서와 다를 수 있다.
- Set의 빠른검색 : 데이터의 중복을 방지하고 빠른 조회가 가능토록 최적화 되어있다.
- Set의 예시 : 회원 ID 집합, 고유 항목 집합 등
▶ 중복 없는 데이터 관리에 유용하다.
• HashCode 에 대해서 알아보기
- HashIndex를 사용하는 Hash 자료구조는 데이터의 추가, 검색, 삭제의 성능이 매우 빠르다.
- int, Integer, char, String, Boolean, 사용자 정의 타입등 모든 타입을 숫자 해시코드를 제공할 수 있어야 한다.
- 자바에서는 모든 객체가 자신만의 해시코드를 표현할 수 있게 Object.hashCode() 를 제공한다.
- IDE의 자동완성기능을 사용하여 equals 와 hashCode를 오버라이딩 한다.
package hello.blog.setEx;
import java.util.Objects;
public class Member {
private String id;
public Member(String id) {
this.id = id;
}
public String getId() {
return id;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Member member = (Member) o;
return Objects.equals(id, member.id);
}
@Override
public int hashCode() {
return Objects.hash(id);
}
@Override
public String toString() {
return "Member{" +
"id='" + id + '\'' +
'}';
}
}
package hello.blog.setEx;
public class HashCodeExMain {
public static void main(String[] args) {
// Object 기본 hashCode는 객체의 참조값을 기반으로 생성한다.
Object obj1 = new Object();
Object obj2 = new Object();
System.out.println("obj1.hashCode() = " + obj1.hashCode());
System.out.println("obj2.hashCode() = " + obj2.hashCode());
// 각 클래스마다 hashCode()는 이미 오버라이딩 되어 있다.
Integer i = 10;
String strA = "A";
String strB = "AB";
System.out.println("10.hashCode = " + i.hashCode());
System.out.println("strA.hashCode = " + strA.hashCode());
System.out.println("strB.hashCode = " + strB.hashCode());
// hashCode 에는 마이너스 값이 들어올 수 있다.
System.out.println("-1.hashCode = " + Integer.valueOf(-1).hashCode());
// 둘은 같을까 ? 인스턴스는 다르지만 equals는 같다.
Member member1 = new Member("idA");
Member member2 = new Member("idA");
// equals, hashCode 를 오버라이딩 한 경우와 하지않은 경우 비교
System.out.println("(member1 == member2) = " + (member1 == member2));
System.out.println("member1 equals member2 = " + member1.equals(member2));
System.out.println("member1.hashCode() = " + member1.hashCode());
System.out.println("member2.hashCode() = " + member2.hashCode());
}
}
// 결과
obj1.hashCode() = 960604060
obj2.hashCode() = 1721931908
10.hashCode = 10
strA.hashCode = 65
strB.hashCode = 2081
-1.hashCode = -1
(member1 == member2) = false
member1 equals member2 = true
member1.hashCode() = 104101
member2.hashCode() = 104101
// Object가 제공하는 hashCode()는 객체의 참조값을 해시코드로 사용
// Integer, String 같은 경우 데이터의 값이 같으면 같은 hashCode를 반환
▶ 자바가 기본적으로 제공하는 클래스들은 대부분 hashCode()를 재정의 해두었다.
▶ 객체를 직접 만들어야 하는 경우, hashCode()를 재정의 하면 됨
▶ 해시자료 구조에 데이터를 저장하는 경우, hashCode()를 구현하는것이 선행되어야 한다.
▶ 해시 자료 구조를 사용할 때는 hashCode() 는 물론이고, equals() 도 반드시 재정의해야 한다.
( hashCode() , equals() 를 사용하게 된다. 그런데 Object 가 기본으로 제공하는 기능은 단순히 인스턴스의
참조를 기반으로 작동한다. )
▶ 자바가 제공하는 해시 함수들을 사용하면 같은 입력에 대해 동일한 해시 코드를 반환하여, 해시 코드를 한곳에
뭉치지 않게하고 균일하게 분포되게 한다.
• 제네릭과 인터페이스를 도입하여 타입안정성을 높일 수 있다.
package hello.blog.setEx2;
public interface MySet<E> {
boolean add(E element);
boolean remove(E value);
boolean contains(E value);
}
// 제네릭 타입을 사용함으로써 아래와 같은 이점을 챙길 수 있다.
1) 유연성: 다양한 타입의 데이터를 저장할 수 있습니다.
2) 타입 안정성: 컴파일 시점에 타입 오류를 검사하여 안전한 코드를 작성할 수 있습니다.
3) 코드 재사용성: 한 번 정의된 인터페이스를 다양한 상황에서 재사용할 수 있습니다.
package hello.blog.setEx2;
import java.util.Arrays;
import java.util.LinkedList;
public class MyHashSet<E> implements MySet<E> {
static final int DEFAULT_INITIAL_CAPACITY = 16;
private LinkedList<E>[] buckets;
private int size = 0;
private int capacity = DEFAULT_INITIAL_CAPACITY;
public MyHashSet(int capacity) {
this.capacity = capacity;
initBuckets();
}
private void initBuckets() {
buckets = new LinkedList[capacity];
for ( int i = 0; i < capacity; i++ ) {
buckets[i] = new LinkedList<>();
}
}
@Override
public boolean add(E value) {
int hashIndex = hashIndex(value);
LinkedList<E> bucket = buckets[hashIndex];
if (bucket.contains(value)) {
return false;
}
bucket.add(value);
size++;
return true;
}
@Override
public boolean contains(E searchValue) {
int hashIndex = hashIndex(searchValue);
LinkedList<E> bucket = buckets[hashIndex];
return bucket.contains(searchValue);
}
@Override
public boolean remove(E value) {
int hashIndex = hashIndex(value);
LinkedList<E> bucket = buckets[hashIndex];
boolean result = bucket.remove(value);
if (result) {
size--;
return true;
} else {
return false;
}
}
private int hashIndex(Object value) {
//hashCode의 결과로 음수가 나올 수 있다. abs()를 사용해서 마이너스를 제거한다.
return Math.abs(value.hashCode()) % capacity;
}
public int getSize() {
return size;
}
@Override
public String toString() {
return "MyHashSet{" +
"buckets=" + Arrays.toString(buckets) +
", size=" + size +
", capacity=" + capacity +
'}';
}
}
package hello.blog.setEx2;
public class MyHashSetMain {
public static void main(String[] args) {
MySet<String> set = new MyHashSet<>(10);
set.add("A");
set.add("B");
set.add("C");
System.out.println(set);
// 검색
String searchValue = "A";
boolean result = set.contains(searchValue);
System.out.println("set.contains(" + searchValue + ") = " + result);
}
}// 결과
MyHashSet{buckets=[[], [], [], [], [], [A], [B], [C], [], []], size=3, capacity=10}
set.contains(A) = true
※ 제네릭에 대한 설명은 아래 링크에서 알 수 있다.
https://baby9235.tistory.com/123
[ JAVA ] 제네릭 ( Generic )
제네릭 ( Generic ) 1) Generic 이란 ? • Generic에 대해 알아보자- Class , Interface, Method 에 타입 매개변수를 추가해 코드의 유연성과 안정성을 높일수 있는 기능- 다양한 타입을 처리가 가능토록 하
baby9235.tistory.com
• 자바가 제공하는 Set
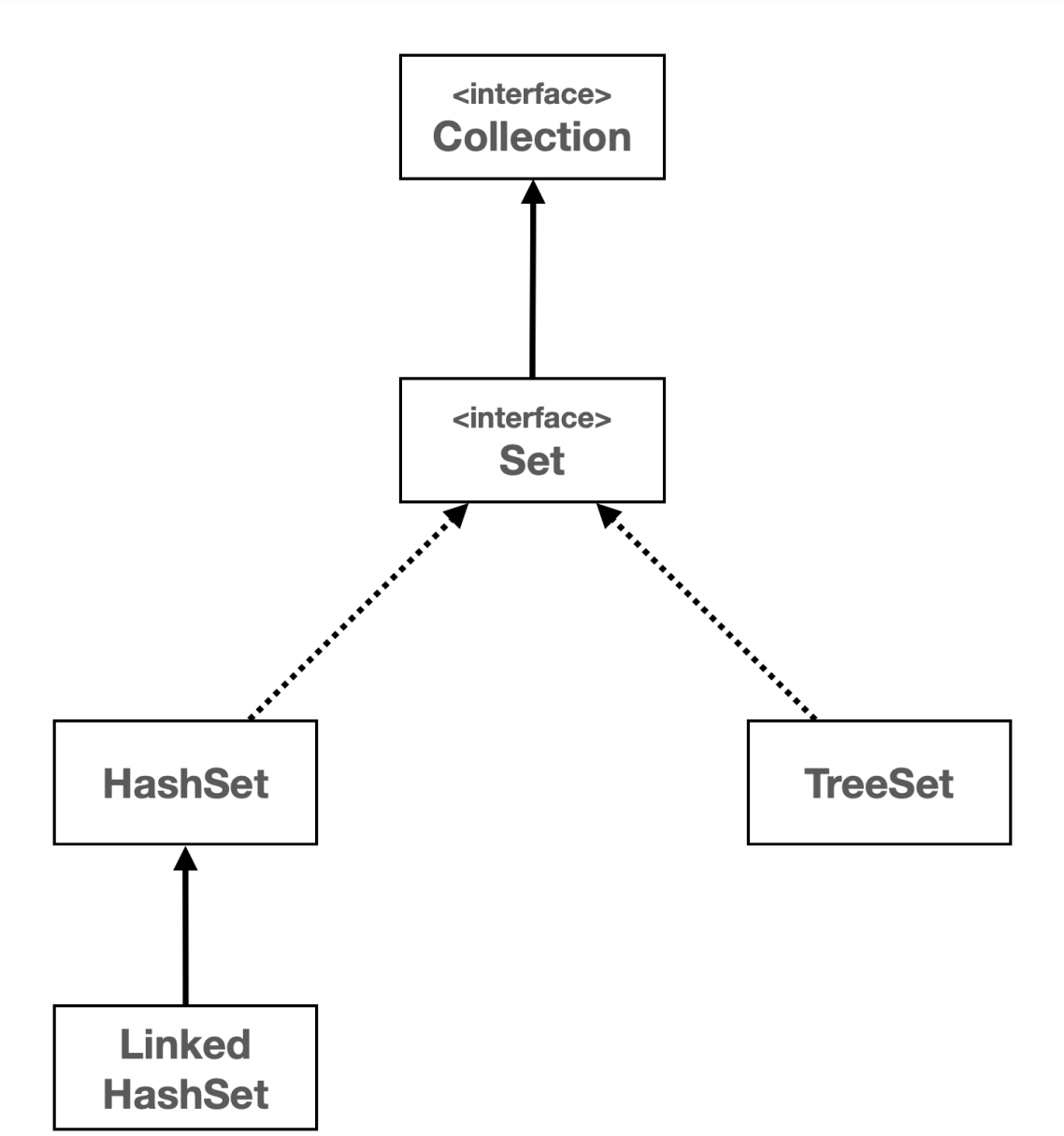
- Set 인터페이스는 java.util 패키지의 컬렉션 프레임워크에 속하는 인터페이스 중 하나
- Set 인터페이스는 중복을 허용하지 않는 유일한 요소의 집합을 나타낸다.
- Set은 순서를 보장하지 않으며, 특정 요소가 집합에 있는지의 여부를 확인하는데 최적화 되어 있다.
• Set 주요 메서드
| 메서드 | 설명 |
| add( Element e ) | 지정된 요소를 Set 에 추가 ( 중복인 경우, false 를 반환 ) |
| contains( Object o ) | Set 에 특정 요소가 있는지 확인 ( 요소가 있으면 true 반환 ) |
| remove( Object o ) | 지정된 요소를 Set에서 제거 ( 제거에 성공하면 true 반환 ) |
| clear() | Set 의 모든 요소를 제거 |
| size() | Set 의 요소의 개수 반환 |
| isEmpty() | Set 가 비어있는지 확인 ( 비어있으면 true 반환 ) |
| iterator() | Set 의 모든 요소를 순회하여 객체를 반환 |
| toArray() | Set 의 모든 요소를 배열로 변환하여 반환 |
• Java가 제공하는 HashSet, LinkedHashSet, TreeSet 예시 보기
package hello.blog.javaSet;
import java.util.*;
public class JavaSetMain {
public static void main(String[] args) {
run(new HashSet<>());
run(new LinkedHashSet<>());
run(new TreeSet<>());
}
private static void run(Set<String> set ) {
System.out.println("set = " + set.getClass());
set.add("C");
set.add("B");
set.add("A");
set.add("1");
set.add("2");
// 반복자 객체 생성
Iterator<String> iterator = set.iterator();
// 반복할 요소가 남아있을때까지 반복
while (iterator.hasNext()) {
// 다음 데이터 반환
System.out.print(iterator.next() + " ");
}
System.out.println();
}
}
// 결과
set = class java.util.HashSet
A 1 B 2 C
set = class java.util.LinkedHashSet
C B A 1 2
set = class java.util.TreeSet
1 2 A B C
// HashSet : 입력한 순서를 보장하지 않는다.
// LinkedHashSet : 입력한 순서를 정확히 보장한다.
// TreeSet : 데이터 값 기준으로 정렬
▶ 실무에서는 Set 이 필요한 경우 HashSet 을 가장 많이 사용한다. 그리고 입력 순서 유지, 값 정렬의 필요에 따라서 LinkedHashSet , TreeSet 을 선택하면 된다.
※ 해당 내용은 인프런 김영한 강사님의 "실전 자바 중급2" 인강의 자료와 예시들을 참고하였습니다
'■ Programming Skills > JAVA' 카테고리의 다른 글
| [ JAVA ] 제네릭 ( Generic ) (3) | 2024.10.26 |
|---|---|
| [ JAVA ] 컬렉션 프레임워크 (3) - Map (3) | 2024.10.24 |
| [ JAVA ] 컬렉션 프레임워크 (1) - List (3) | 2024.10.23 |
| [ JAVA ] 예외 처리 (2) (0) | 2024.08.21 |
| [ JAVA ] 예외 처리 (1) (0) | 2024.08.21 |



